Тематическое моделирование (LDA)
В Деткорпусе реализован поиск по фрагментам произведений, содержащим определенную тему. Тематика определяется автоматически с помощью алгоритма тематического моделирования LDA. Тематическое моделирование — это метод машинного обучения, который позволяет сгруппировать слова, встречающиеся вместе в одних и тех же контекстах, в «топики» — условные лексические группы. Топики во многих случаях связаны с понятной для человека предметной областью, то есть поддаются интерпретации. В свою очередь, каждое словоупотребление в корпусе алгоритм относит к тому или иному топику. В результате можно посчитать, к каким топикам отнесена большая часть слов в каждом фрагменте текста и получить таким образом тематическую характеристику фрагмента.
В Деткорпусе применена следующая процедура тематического моделирования:
- Все произведения разбиты на фрагменты по 500 токенов (около
двух—четырех страниц текста). Фрагменты каждого произведения
обозначаются последовательными номерами (поле метаданных
f.id). - Построено три тематических модели — на 100, 200 и 300 тем, охватывающие целиком весь корпус (от 1920х до 2010х, включая художественные тексты и нон-фикшн). В качестве документа в модели использовались 500-словные фрагменты. Все слова лемматизированы (приведены к начальной форме), удалены стоп-слова (предлоги, союзы, местоимения).
- Для всех получившихся при моделировании тем (топиков) автоматически
сгенерированы метки вида
100_бой_танк_война. Метка состоит из номера темы (темы пронумерованы по порядку, от самых объемных, включающих наибольшее количество словоупотреблений, к самым «маленьким») и трех самых частотных слов в данной теме. - В метаданных каждого фрагмента указаны те темы, которые
представлены не менее чем 25 словоупотреблениями в данном
фрагменте. Темы указаны в полях
f.lda100(модель на 100 тем),f.lda200(200 тем) иf.lda300(300 тем).
Инструкция по поиску с учетом тематики фрагмента
Один из самых простых способов задействовать тематическую информацию
при поиске — воспользоваться ограничением конкорданса по типу
текстов (Text types). Для этого достаточно:
- Открыть базовую поисковую форму, ввести запрос (слово):

- Нажать на галочку рядом с Text types, раскроется список всех
доступных полей метаданных. В конце списка находятся поля
тематических моделей: f.lda100, f.lda200 и f.lda300.
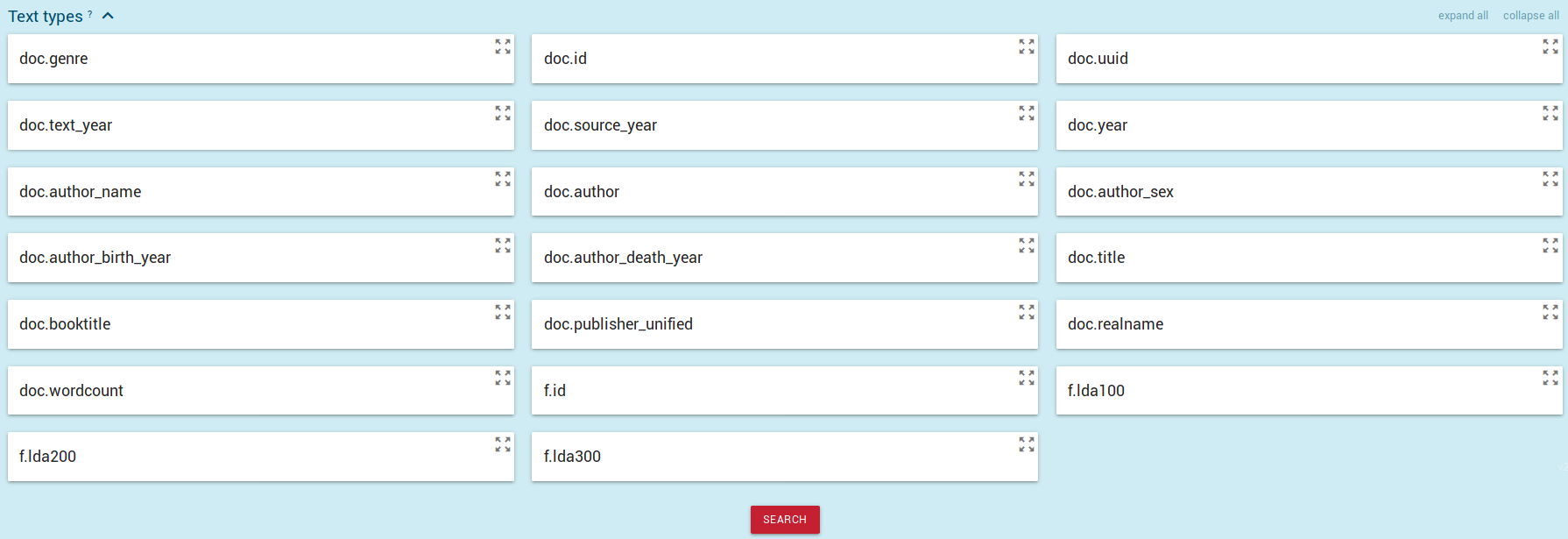
- Нажать на одно из полей, например, f.lda300, и начать вводить
ключевое слово для поиска в названиях тем. В нашем случае начнем
вводить "шпион". В выпадающем списке будут показаны все совпадающие
темы:
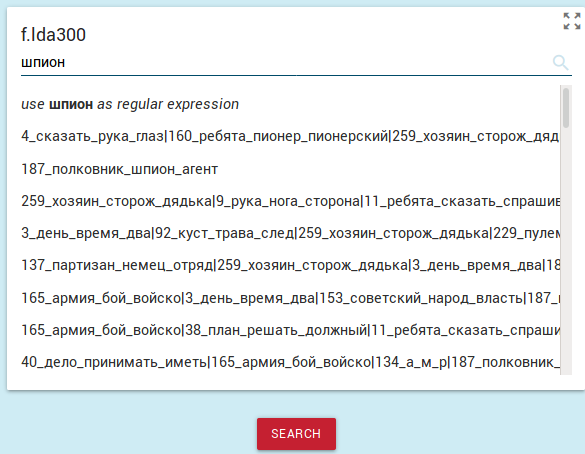
- Для дальнейшего поиска с учетом темы следует выбрать тот пункт из
списка, где искомая тема не объединена с другими. Выбранная тема
отобразится наверху блока:
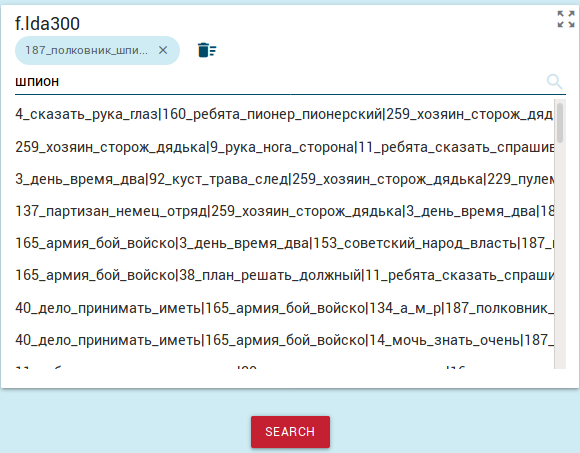 .
. - Дальше можно запускать поиск, нажав на кнопку SEARCH, и получить
искомый конкорданс:
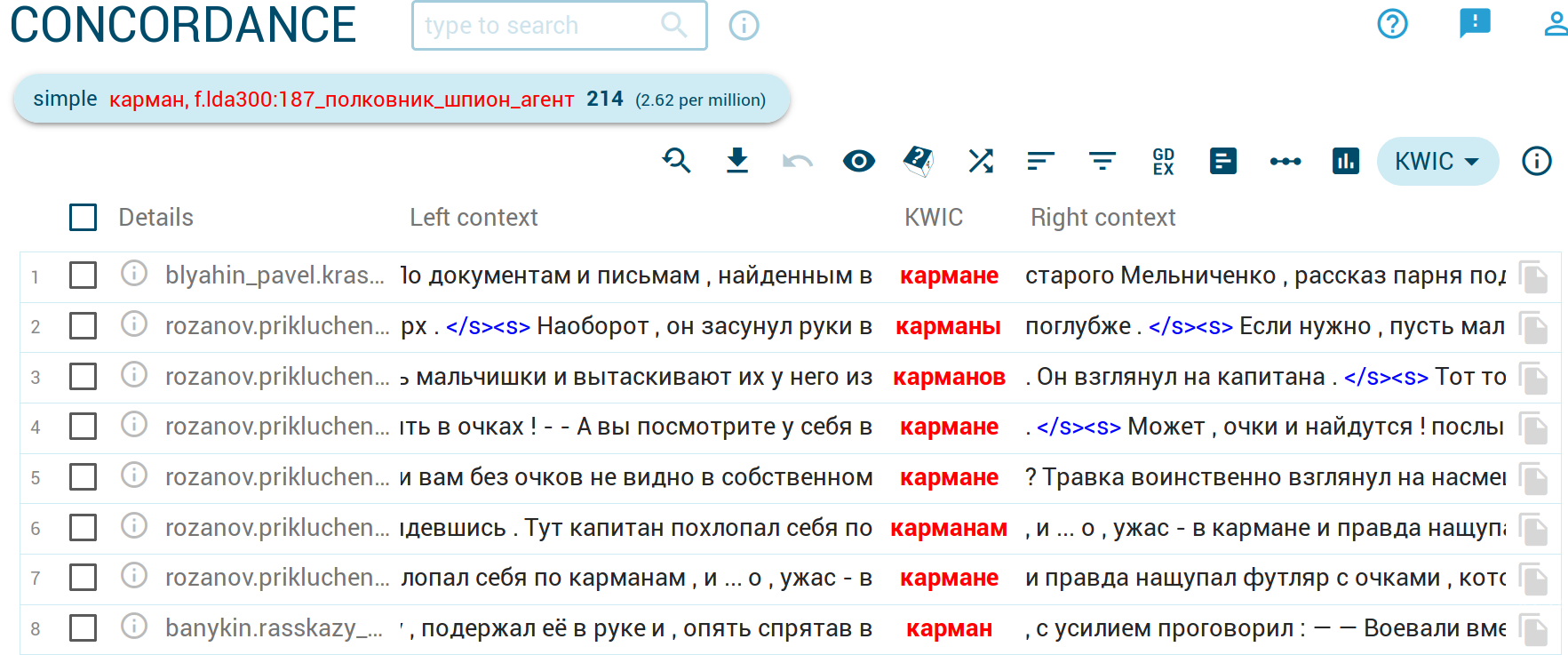 .
.
Ответы на вопросы
- Можно ли при тематическом поиске выбрать более одной темы? — Можно. Даже из разных моделей одновременно!
- Как посмотреть полный список тем? — Полный список подгружается после нажатия на тематический блок, например, f.lda100, но его не очень удобно просматривать. Поэтому лучше пользоваться поиском, как объясняется в инструкции выше. Мы работаем над более удобным интерфейсом для изучения тематических моделей корпуса, следите за объявлениями.
- Почему в конкордансе встречаются фрагменты, не относящиеся к заданной теме? — Во-первых, фрагменты достаточно велики (500 слов), и найденное в конкордансе слово может отстоять достаточно далеко от появления темы. Во-вторых, алгоритмы тематического моделирования несовершенны. Они ни в какой мере не обладают «пониманием» текста, и выделяют темы, опираясь лишь на формальные критерии совместной встречаемости слов. Часто выделенная автоматически тема (топик) может включать лексику из смежных семантических областей, что не всегда хорошо отражается в метке темы, содержащей лишь три самых частотных слова. Например, тема «полковник_шпион_агент» группирует лексику, связанную с описанием шпионов, военных и детективов, поэтому она встречается и в шпионских повестях 1930х, и в детских детективах 1990х. Можно относиться к этому как к ошибке тематической атрибуции, а можно как к эмпирической подсказке и поводу задуматься о типологических обобщениях. В любом случае стоит помнить, что тематический поиск в корпусе — это в первую очередь инструмент, позволяющий направленно сузить поиск в частотных запросах, выбрав из тысяч возможных совпадений набор более релевантных.